
Machine Learning For Anomaly Detection opens doors to a world of possibilities, where data reveals hidden anomalies and sparks innovation. Dive into the realm of anomaly detection, where patterns emerge from chaos, guiding us towards informed decisions and breakthroughs.
From real-world applications to evaluation metrics, this journey explores the depths of anomaly detection with machine learning, shedding light on its significance across industries and the challenges faced along the way.
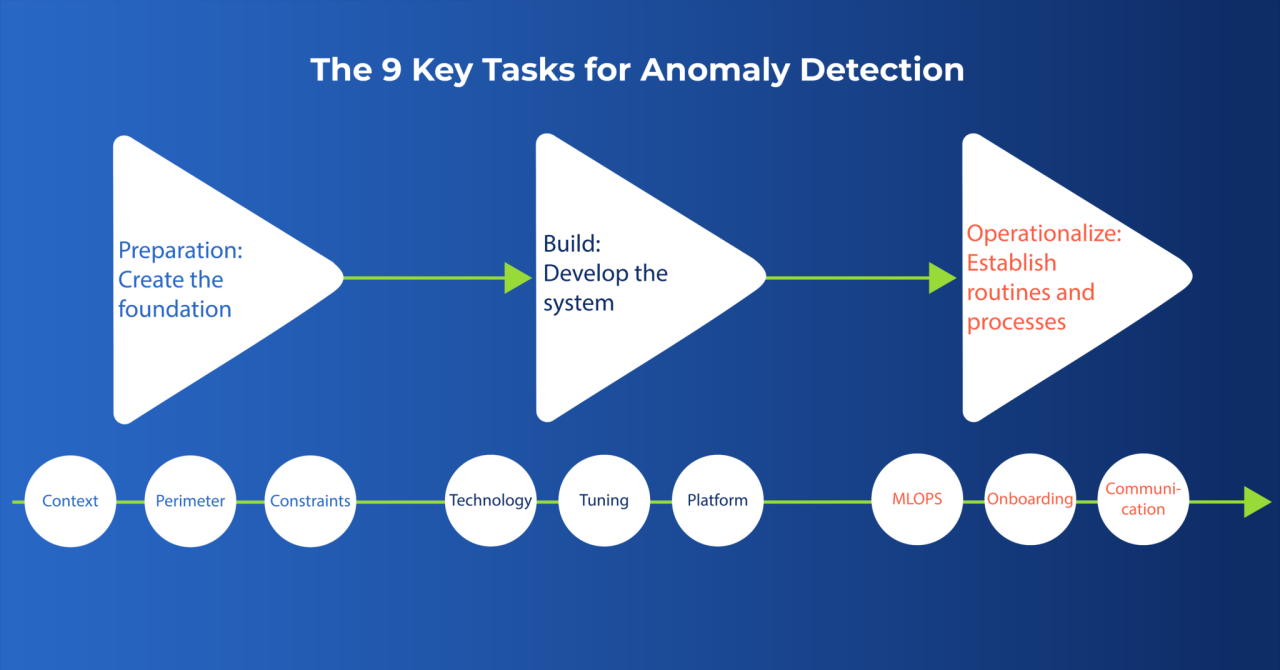
Introduction to Machine Learning for Anomaly Detection
Anomaly detection in machine learning involves identifying patterns in data that do not conform to expected behavior. This technique is crucial for detecting outliers, deviations, or irregularities that may indicate potential issues or threats.
Real-world applications of anomaly detection span across various industries. In finance, anomaly detection can help detect fraudulent activities such as credit card fraud or money laundering. In cybersecurity, anomaly detection is used to identify unusual network traffic that could signal a cyber attack. In healthcare, anomaly detection can assist in detecting abnormal medical test results or patient data.
Importance of Anomaly Detection
Anomaly detection plays a vital role in safeguarding systems and processes in different sectors. Here are some key points highlighting the importance of anomaly detection:
- Early detection of fraud and security breaches
- Improving operational efficiency by identifying irregularities in processes
- Enhancing decision-making by flagging outliers in data
- Ensuring data integrity and quality by identifying anomalies
Types of Anomalies
Anomalies in data can be classified into different types based on their characteristics and impact on the dataset. Understanding these types is crucial for effectively detecting and handling anomalies using machine learning algorithms.
Point Anomalies:
Point anomalies are individual data points that deviate significantly from the rest of the dataset. These anomalies are isolated and can be detected by looking at individual data points without considering the context. For example, a sudden spike in website traffic or an unusually high purchase amount can be considered as point anomalies.
Contextual Anomalies:
Contextual anomalies occur when a data point is anomalous only in a specific context or subset of the data. These anomalies may not stand out when looking at the dataset as a whole but become apparent when considering additional information or features. For instance, a temperature reading that is normal for one location may be considered anomalous in another context.
Collective Anomalies:
Collective anomalies involve a group of data points that together exhibit anomalous behavior, even though individual data points may appear normal. These anomalies are detected by analyzing the relationships and interactions among data points. An example of a collective anomaly is fraudulent behavior in a network where multiple seemingly normal transactions collectively indicate suspicious activity.
Understanding the different types of anomalies is essential for developing accurate anomaly detection models that can effectively identify and address anomalies in various datasets.
Common Techniques for Anomaly Detection
Anomaly detection is a critical task in machine learning, and there are several popular techniques used to detect anomalies in data. Let’s explore some of the common techniques and their strengths and weaknesses.
Isolation Forest
Isolation Forest is a popular algorithm for anomaly detection that works by isolating anomalies instead of profiling normal data points. It is efficient for high-dimensional data and can handle large datasets well. However, it may struggle with data that has a high level of noise.
One-Class SVM
One-Class SVM is another commonly used algorithm for anomaly detection that learns the boundaries of normal data points and flags any data points outside those boundaries as anomalies. It works well for data with non-linear boundaries but may struggle with highly imbalanced datasets.
Autoencoders
Autoencoders are neural networks that learn to encode and decode input data. They can be used for anomaly detection by reconstructing normal data points accurately and flagging anomalies based on reconstruction errors. Autoencoders are effective for detecting complex anomalies but may require a large amount of training data.
These techniques have their own strengths and weaknesses, making them suitable for different types of data. Isolation Forest is efficient for high-dimensional data, One-Class SVM works well for non-linear boundaries, and Autoencoders are effective for detecting complex anomalies. Depending on the nature of the data and the specific requirements of the anomaly detection task, one can choose the most appropriate technique to achieve accurate results.
Evaluation Metrics for Anomaly Detection Models: Machine Learning For Anomaly Detection
When it comes to assessing the performance of anomaly detection models, various evaluation metrics play a crucial role in determining their effectiveness. These metrics help in quantifying how well the models are able to identify anomalies within a given dataset.
Precision, Machine Learning For Anomaly Detection
Precision is a metric that measures the proportion of true positives (correctly identified anomalies) among all instances predicted as anomalies by the model. A high precision score indicates that the model has a low rate of false positives, meaning that when it flags an instance as an anomaly, it is likely to be correct.
- Formula:
Precision = TP / (TP + FP)
- Example: In fraud detection, precision is vital as incorrectly flagging legitimate transactions as anomalies can lead to customer dissatisfaction.
Recall
Recall, also known as sensitivity, measures the proportion of true anomalies that are correctly identified by the model. A high recall score indicates that the model captures a large percentage of actual anomalies present in the data.
- Formula:
Recall = TP / (TP + FN)
- Example: In network intrusion detection, recall is crucial to ensure that all malicious activities are detected to prevent potential threats.
F1 Score
The F1 score is the harmonic mean of precision and recall, providing a balance between the two metrics. It considers both false positives and false negatives, making it a useful metric to evaluate the overall performance of an anomaly detection model.
- Formula:
F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
- Example: Anomaly detection in medical diagnosis requires a good F1 score to ensure both precision and recall are optimized for accurate predictions.
ROC-AUC
Receiver Operating Characteristic – Area Under the Curve (ROC-AUC) is a metric that evaluates the trade-off between true positive rate and false positive rate across different threshold values. A higher ROC-AUC score indicates better model performance.
- Formula:
ROC-AUC ranges from 0 to 1, with 1 indicating a perfect model.
- Example: In credit card fraud detection, ROC-AUC is essential to balance the rate of correctly identifying fraud cases while minimizing false alarms.
Challenges in Anomaly Detection with Machine Learning
Anomaly detection using machine learning presents several challenges that can impact the accuracy and effectiveness of the models. These challenges include issues related to imbalanced data, noisy data, and interpretability of results. Overcoming these challenges is crucial for developing robust anomaly detection systems.
Imbalanced Data
Imbalanced data occurs when one class of data significantly outnumbers the other class, leading to biased models. In anomaly detection, the anomaly class is usually the minority class, making it challenging for the model to accurately detect anomalies. Strategies to address imbalanced data in anomaly detection include:
- Using sampling techniques such as oversampling or undersampling to balance the dataset.
- Applying algorithmic approaches like adjusting class weights or using ensemble methods to handle imbalanced data.
- Utilizing anomaly detection algorithms specifically designed for imbalanced data, such as one-class SVM or isolation forests.
Noisy Data
Noisy data contains errors, outliers, or irrelevant information that can affect the performance of anomaly detection models. Dealing with noisy data is crucial for accurate anomaly detection. Techniques to mitigate the impact of noisy data include:
- Preprocessing techniques like outlier removal, data cleaning, and normalization to reduce noise in the dataset.
- Using robust anomaly detection algorithms that are less sensitive to noise, such as DBSCAN or LOF.
- Implementing feature selection methods to focus on relevant features and reduce the influence of noisy data.
Interpretability of Results
Interpretability is essential for understanding how anomaly detection models make decisions and providing actionable insights to stakeholders. Black-box models can be challenging to interpret, leading to a lack of trust in the results. Strategies to enhance the interpretability of anomaly detection models include:
- Utilizing explainable AI techniques like SHAP values or LIME to interpret model predictions and feature importance.
- Visualizing the decision boundaries and anomalies detected by the model to gain insights into its behavior.
- Combining interpretable models with complex algorithms to balance accuracy and interpretability in anomaly detection.
FAQ
What are the different types of anomalies that can be detected?
Point anomalies, contextual anomalies, and collective anomalies are the main types that can be identified using machine learning algorithms.
Which are some popular machine learning algorithms used for anomaly detection?
Isolation Forest, One-Class SVM, and Autoencoders are commonly employed techniques for detecting anomalies.
How do evaluation metrics help in measuring the effectiveness of anomaly detection algorithms?
Evaluation metrics such as precision, recall, F1 score, and ROC-AUC provide insights into the performance of anomaly detection models and their accuracy.
What are some common challenges faced in anomaly detection with machine learning?
Issues related to imbalanced data, noisy data, and result interpretability are common challenges that need to be addressed for accurate anomaly detection.